
以前にTERAOKAのレジのデータ(複数のExcelファイル)を一つのワークシートに集計し、そこから弥生会計への入力データを作成するExcelのマクロについての記事を掲載しましたが、
TERAOKAのレジの売上データをExcelで1つのワークシートに集計し、弥生会計の入力用データを作成する
同じことをPythonでやってみようと思います。
今回は、「複数のExcelファイルのデータを一つのワークシートに集計する」というところまでです。
プログラムのコードは以下の通りです。
import pandas as pd
import openpyxl
import glob
#XLSのファイルを開いてファイル内のデータをDataFrameに取り込み
#list内の項目名で検索してその金額をExcelのファイルに転記する
files = glob.glob('*.XLS')
list = ['現計','商品券','クレジット','PayPay','商品券値引','商品券値引き'\
,'内税対象額計(8%)','内税額計(8%)','内税対象額計(10%)'\
,'内税額計(10%)','外税対象額計(8%)','外税額計(8%)'\
,'外税対象額計(10%)','外税額計(10%)']
wb = openpyxl.load_workbook('org.xlsx')
sheet = wb['sheet1']
k = 2
for file in files:
sheet.cell(row = k,column = 15).value = \
file[0:4] +'/' +file[4:6] +'/' +file[6:8]
df = pd.read_excel(file,\
names = ('A','B','C','D','E','F','G'),index_col = None)
for i , j in zip(list,range(1,15)):
if (i in df.values) == True:
sheet.cell(row = k,column = j).value = df.iat[df[df['B'] == i].index[0],6]
else:
sheet.cell(row = k,column = j).value = 0
k = k +1
#Excelのファイルをいったん保存
wb.save('temp.xlsx')
#編集するためにDateFrameに取り込み
df = pd.read_excel('temp.xlsx')
#記述しやすくするために列名を変更する
df.columns = ['A','B','C','D','E','F','G','H','I' \
,'J','K','L','M','N','O','P','Q','R','S','T','U','V','W']
#売上金額がすべて0である行をリストにする
df_drop = df[(df['A'] == 0 ) & (df['B'] == 0 ) \
& (df['C'] == 0 ) & (df['D'] == 0 ) & (df['E'] == 0 ) \
& (df['F'] == 0 ) & (df['G'] == 0 ) & (df['H'] == 0 ) \
& (df['I'] == 0 ) & (df['J'] == 0 ) & (df['K'] == 0 ) \
& (df['L'] == 0 ) & (df['M'] == 0 ) & (df['N'] == 0 )]
#売上金額がすべて0である行を削除して
#DateFrameを削除後のものに入れ替える
df.drop(df_drop.index,inplace = True)
#計算式の代入
df['Q'] = df['A'] + df['B'] + df['C'] + df['D'] + df['E'] + df['F']
df['R'] = df['G'] + df['H'] + df['I'] + df['J'] + df['K'] + df['L'] + df['M'] + df['N']
df['S'] = df['Q'] - df['R']
df['T'] = df['G'] +df['H'] + df['K'] + df['L'] - df['B'] - df['E'] - df['F']
df['U'] = df['I'] + df['J'] + df['M'] + df['N']
df['V'] = df['A']
#日付でソート
df.sort_values('O',inplace = True)
#列名を元に戻す
df.columns = ['現計','商品券','クレジット','PayPay','商品券値引'\
,'商品券値引き','内税対象額計(8%)','内税額計(8%)'\
,'内税対象額計(10%)','内税額計(10%)','外税対象額計(8%)'\
,'外税額計(8%)','外税対象額計(10%)','外税額計(10%)',\
'日付','','支払手段計','売上計','差額','8%-商品券','10%',\
'現計','入金日']
#Excelのファイルに書き出し
df.to_excel('teraoka_shukei.xlsx',index = False)
前提としてはカレントディレクトリに、
- 「20200401_取引別レポート.XLS」
- 「20200402_取引別レポート.XLS」 ・・・・
というように日別の*.XLSファイルが一ヶ月分あり(「取引別レポート」のファイルの拡張子はデフォルトで「*.xls」ではなく「*.XLS」と大文字になっていました。)、
Excelのファイルを書き込みするときの原稿となる「org.xlsx」が保存されているものとします。
こういった形式のファイルです。
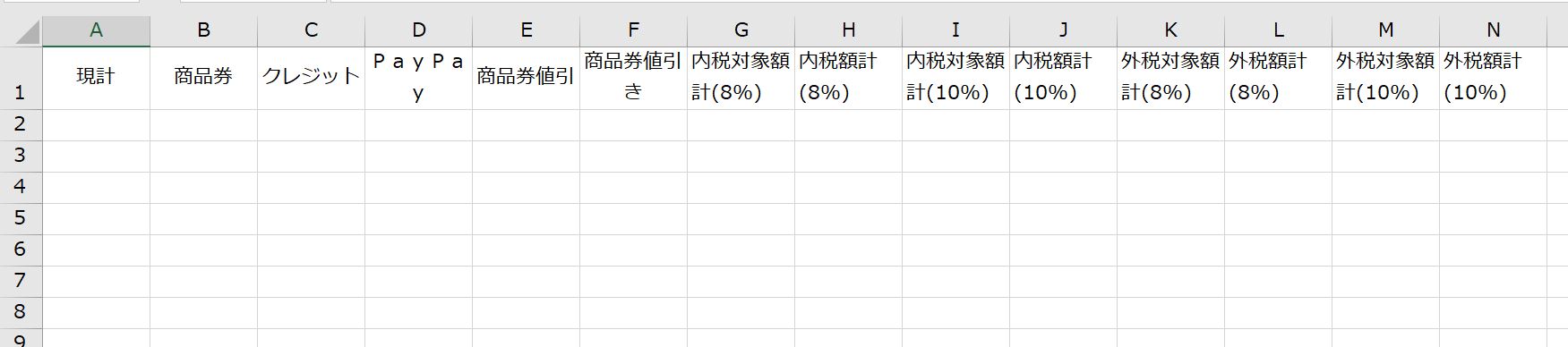
最もわかりにくいと思われるのが
sheet.cell(row = k,column = j).value = df.iat[df[df['B'] == i].index[0],6]
の部分ですが、確認のために
import pandas as pd
df = pd.read_excel('20200402_取引別レポート.XLS',\
names = ('A','B','C','D','E','F','G'),index_col = None)
print(df['B'] == '現計')
print(df[df['B'] == '現計'])
print(df[df['B'] == '現計'].index[0])
print(df.iat[df[df['B'] == '現計'].index[0],6])
というコードを書いて実行してみると、
0 False
1 False
2 False
(省略)
37 False
38 True
39 False
(省略)
47 False
48 False
49 False
Name: B, dtype: bool
A B C D E F G
38 NaN 現計 NaN NaN 55.0 件 114113
38
114113
というようにコンソールに表示されます。
- df[‘B’] == ‘現計’ ・・・ DataFrameのB列の要素が’現計’である行についてはTrueを、そうでない行についてはFalseを返す
- df[df[‘B’] == ‘現計’] ・・・ B列の要素が’現計’である行全体
- df[df[‘B’] == ‘現計’].index[0] ・・・ B列の要素が’現計’である行(1行しかないですが)の0列目の0行目の要素。該当の行が(0行目から始まった場合の)38行目であることがわかる
- df.iat[df[df[‘B’] == ‘現計’].index[0],6] ・・・ DataFrameの38行目の(0列目から始まった場合の)6列目に求める金額のデータがある
ということになります。ここは本当はもう少しわかりやすく書くことができるかも知れません。