
プログラムの書き方の例
file_path = os.path.dirname(__file__) + '/hoshu_merge.xlsm'
with pd.ExcelWriter(file_path,mode='a',if_sheet_exists='replace',engine='openpyxl'
,engine_kwargs={'keep_vba': True}) as writer:
df_temp4.to_excel(writer, sheet_name='tatekae',merge_cells=False,index=False)ExcelWriter の Parameter に、「engine_kwargs={‘keep_vba’: True}」を追加することによって、既存のExcelの.xlsmファイルに書き込みをすることができました。
以前の書き方
以前は以下のようにPythonのプログラムを書いていました。
file_path = os.path.dirname(__file__) + '/hoshu_merge.xlsm'
with pd.ExcelWriter(file_path) as writer:
writer.book = openpyxl.load_workbook(file_path,keep_vba='true')
writer.book.remove(writer.book['tatekae'])
df_temp4.to_excel(writer, sheet_name='tatekae',merge_cells=False,index=False)一応これで動作していたのですが、いつの間にか実行時に次のようなメッセージが出力されるようになりました。
FutureWarning: Setting the `book` attribute is not part of the public API,
usage can give unexpected or corrupted results and will be removed in a future versionどう対応したら良いのかがわからなかったため、Pythonとpandasをバージョンアップしてみました。
python 3.11.4 から 3.11.5 へバージョンアップ
pandas 1.5.3 から 2.1.1 へバージョンアップ
すると今度は、
property 'book' of 'OpenpyxlWriter' object has no setterというエラーメッセージが出てプログラムが動かなくなってしまいました。
解決方法を調べる
それで解決方法を調べました。
pandas.ExcelWriter()で引数mode='a'とすると追記モードになり、
既存のExcelファイルに新たなシートとしてpandas.DataFrameを追加できる。
(https://note.nkmk.me/python-pandas-to-excel/)ということなのですが、その際に「keep_vba=’true’」の状態でExcelのファイルを開き、シートを追加し、保存するための書き方がわかりません。
xlsxのファイルであれば既存のファイルにシートを追加することができるのですが、xlsmファイルだとプログラムを動かしたときにファイルが壊れてしまって開かなくなってしまいます。
結局、https://pandas.pydata.org/docs/reference/api/pandas.ExcelWriter.html のページを参照して、そこに
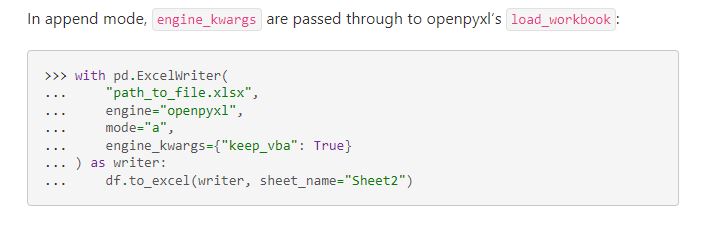
という記述がありましたので、ここから推測してExcelWriter の Parameter に「engine_kwargs={‘keep_vba’: True}」を追加してみました。
すると既存のxlsmファイルにpandasのDataFrameをシートとして追加することができるようになりました。