
この記事に書かれているPythonのプログラムは動作しなくなってしまいましたので、新しいプログラムで記事を書き直しています。そちらを参照してください。
(2023/11/1 追記)
Pythonで「集計」を行う場合にはどのような処理になるのか確認するために、以前にExcelのマクロで行った医療費の集計をPythonで行ってみました。
集計の処理自体は、1行で記述できます。
- Excelのワークシートを読み込む
- 集計する
- 集計結果をExcelのブックに新たなワークシートとして追加する
という手順です。
事前にpandas、openpyxlのインストールが必要です。
読み込み用のExcelのファイルは以下のような様式です。
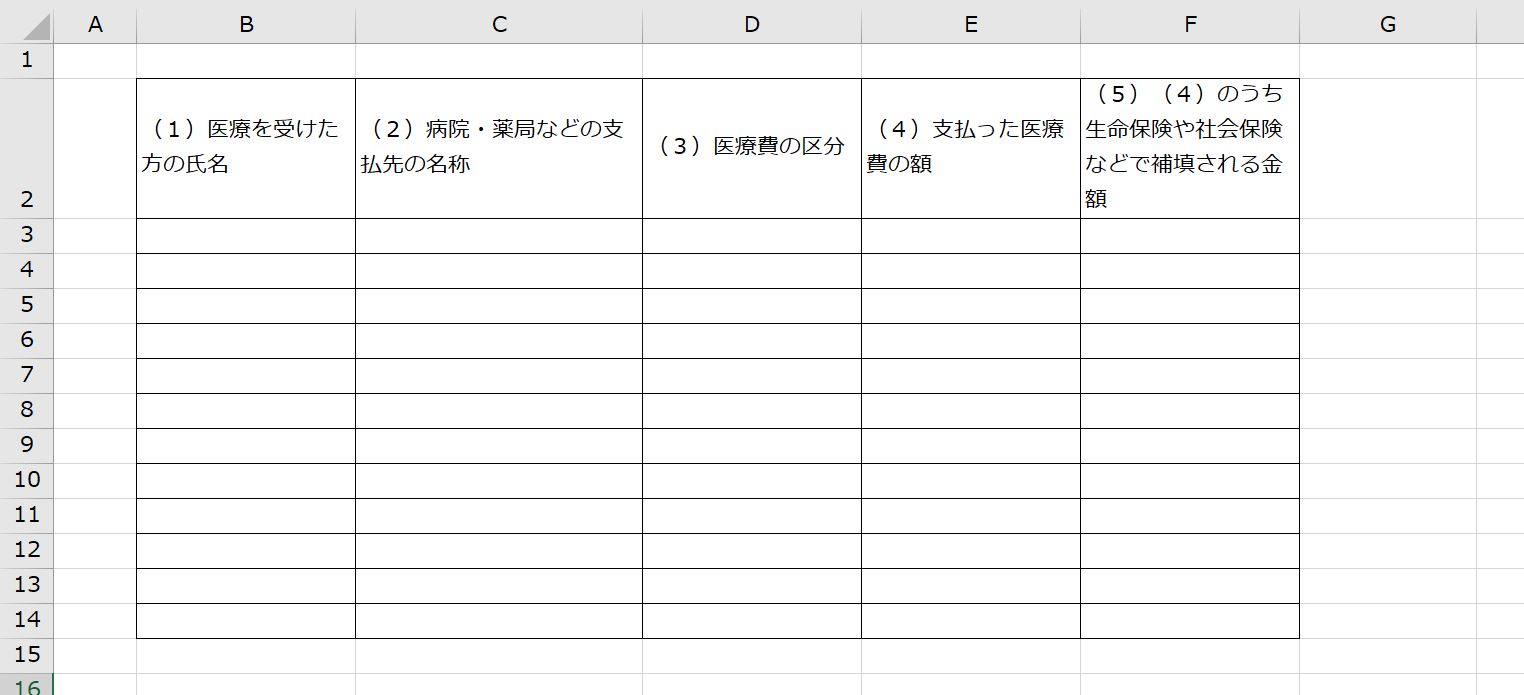
B列からE列にデータが書き込まれているとします。
次のように、氏名・病院名・医療費の区分ごとに集計されます。
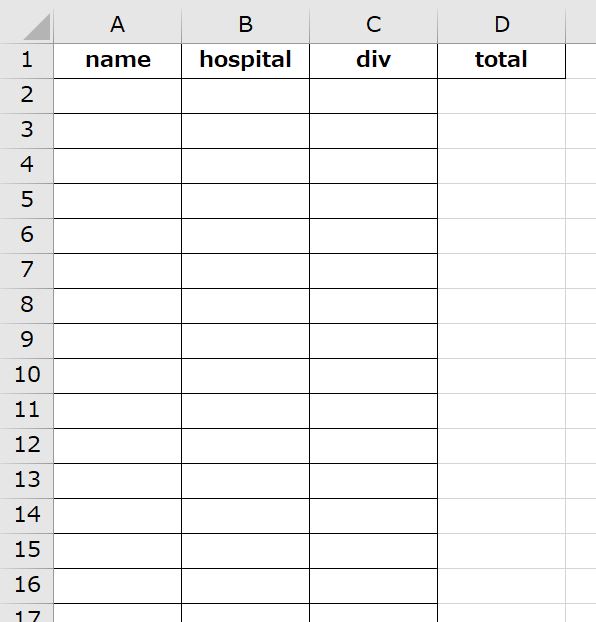
Pythonのプログラムは次のようなものです。
#モジュールのインポート
import pandas as pd
import openpyxl
#ファイル名の指定
path = 'iryohi_shukei.xlsm'
#Excelファイルの読み込み B列からE列を使用 1行目は読み飛ばし
df = pd.read_excel(path, usecols=[1,2,3,4], skiprows=[1])
#列名を指定する
df.columns = ['name','hospital','div','total']
#読み込んだものをcsvファイルに書き出してみる
#df.to_csv('iryohi_shukei.csv',encoding='cp932')
#医療費の集計
grouped = df.groupby(['name','hospital','div'])
#集計結果をcsvファイルに書き出してみる
#grouped.sum().to_csv('iryohi_total.csv',encoding='cp932')
#集計結果をExcelのファイルに新しいシート'shukei_py'として追加する
with pd.ExcelWriter(path) as writer:
writer.book = openpyxl.load_workbook(path,keep_vba='true')
grouped.sum().to_excel(writer, sheet_name='shukei_py',merge_cells=False)
*.pyのPythonのプログラムファイルと読み込み用のExcelのファイルは同じフォルダに保存されていることとします。
Excelのファイルは*.xlsmを前提にしています。*.xlsxのファイルを取り扱う場合には、最後から2行目の「,keep_vba=’true’」を削除してください。
コメント化されているcsvファイルへの書き出しは行う必要はありませんが、処理の途中でデータがどうなっているのかを確認したい場合には実行してみてください。
実際に集計を行っているのは、
grouped = df.groupby([‘name’,’hospital’,’div’])
の1行だけで、Excelのマクロで集計する場合と違いデータをsortしておく必要も無ければ集計用のキーを設定してキーごとに集計するロジックを記述する必要もありません。